
论文阅读 暗光增强 Kindling the Darkness_A Practical Low Light Image Enhancer 及相关论文
论文阅读-暗光增强-Kindling the Darkness_ A Practical Low-light Image Enhancer
Abstract
摘要: 在弱光条件下拍摄的图像通常会出现(部分)能见度低的问题。除了不理想的照明,多种类型的退化,如噪音和由于相机的质量有限的颜色失真,隐藏在黑暗中。换句话说,仅仅提高黑暗区域的亮度将不可避免地放大隐藏的artifacts。这项工作建立了一个简单而有效的点燃黑暗的网络(表示为种类),它的灵感来自Retinex theory,将图像分解成两个部分。一个组件(illumination)负责光的调节,而另一个组件(reflectance)负责降解去除。这样,原始空间就解耦成两个更小的子空间,期望得到更好的正则化/学习。值得注意的是,我们的网络是使用在不同曝光条件下拍摄的成对图像进行训练的,而不是使用任何地面真实反射率和光照信息。我们进行了大量的实验来证明我们的设计的有效性,以及它相对于最先进的替代品的优越性。我们的产品对严重的视觉缺陷有很强的抵抗力,而且用户界面友好,可以任意调节光的亮度。此外,我们的模型在2080Ti GPU上处理VGA分辨率的图像花费不到50ms。以上优点使我们的产品具有实用价值。
一些理解
本文没有开源,做的低光照图像增强,论文标题很有意思。三作是天津大学的郭晓杰,有好几篇相关文章,应该比较靠谱。
这篇文章有意思的一个点是其网络训练时没有使用GT,只是使用一对不同光照程度的图像。这使得这个方法有更好的迁移性,毕竟很多图像处理领域很难找到合适的训练GT。
在网络架构上,其使用了两个分支分别对应反射率和照度。从功能上讲,也可以分为三个模块,分别是层分解、反射率恢复和光照调节。
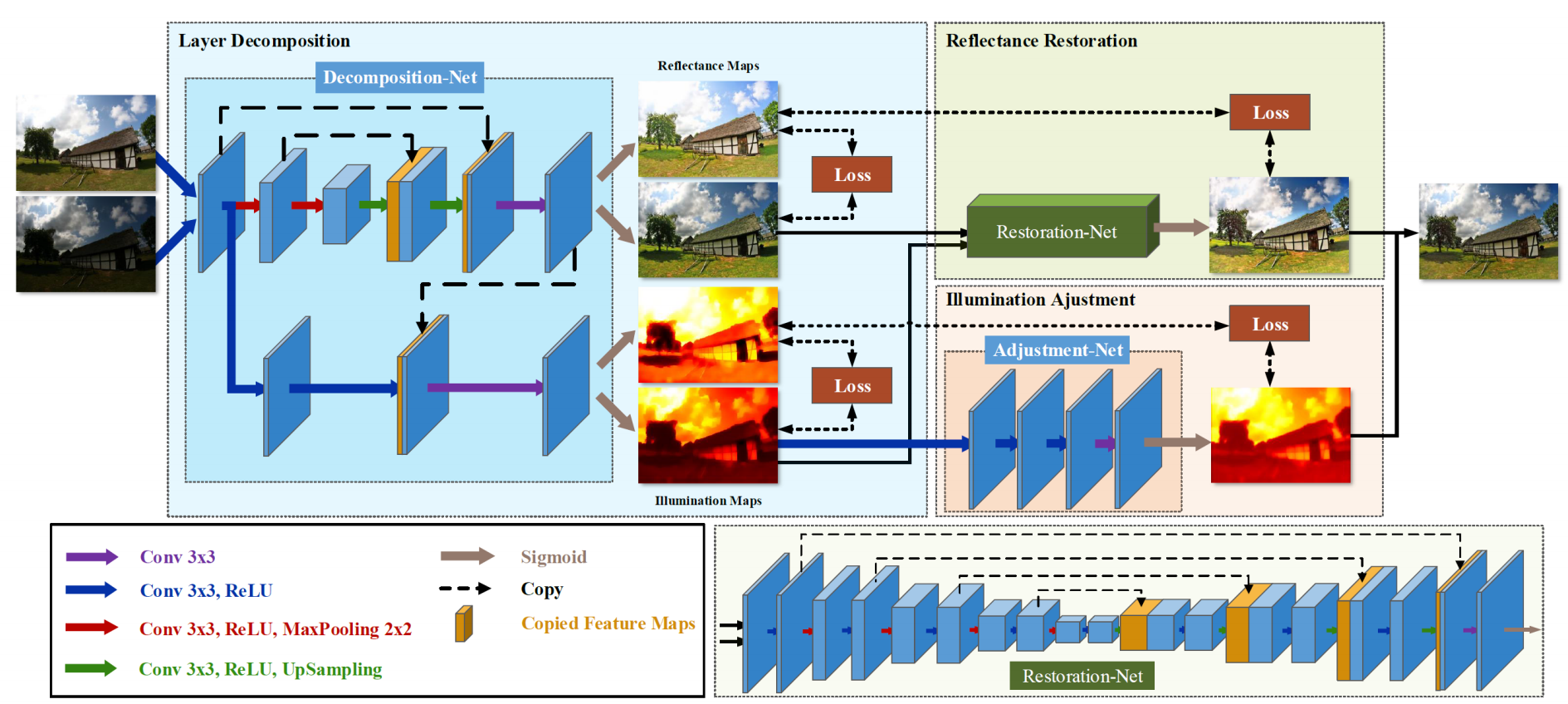
看了一遍还是不太明白。
问题1
光照图的Loss是怎么设计的,什么样子应该大?
照明映射$[L_l,L_h]$应该是分段光滑和相互一致的。
相关工作
人们已经提出了大量的微光图像增强方案。在接下来的文章中,我们将简要回顾与我们密切相关的经典和当代作品。
普通的方法。直观地说,对于全局光线较弱的图像,可以通过直接增大像素值来增强其可视性。但是,如图1的第一种情况所示,包括噪声和颜色失真在内的视觉缺陷在细节处显示出来。对于包含明亮区域的图像,例如图1中的最后两张,这种操作很容易导致(部分)饱和/过度曝光。以直方图均衡化(histogram equalization, HE)[1]、[2]、[3]及其后续[4]、[5]为代表的一条技术线,试图将取值范围映射到[0,1]中,平衡输出的直方图,避免截断问题。这些方法实际上是为了提高图像的对比度。另一种映射方式是伽马校正(GC),它以非线性的方式在每个像素上单独执行。虽然GC可以提高亮度,特别是暗像素的亮度,但是它并没有考虑某个像素与其相邻像素之间的关系。plain方法的主要缺点是几乎不考虑真实的光照因素,这通常使增强的结果在视觉上很脆弱,并且与真实场景不一致。
传统的Illumination-based方法。与普通方法不同的是,这类策略都意识到光照的概念。由Retinex理论[6]得到的关键假设是(彩色)图像可以分解为两个部分,即反射率和光照。早期的尝试包括单标度Retinex (SSR)[7]和多标度Retinex (MSR)[8]。由于受到生成最终结果的方式的限制,输出结果常常看起来不自然,而且在某些地方过度增强了。Wang等人提出了一种名为NPE[9]的方法,该方法可以联合增强对比度并保持光照的自然度。Fu等人开发了一种方法[10],该方法通过融合初始估计的光照图的多个导数来调整光照。然而,这种方法有时会牺牲那些包含丰富纹理的区域的真实感。Lime:Guo等人着重于从一个初始的[11]来估计结构化光照图。这些方法通常假定图像是无噪声和无色彩失真的,并且没有明确考虑图像的退化。在[12]中,为了获得更好的反射率和光照层,设计了一种同时进行反射率和光照估计的加权变分模型(SRIE),然后通过对光照的处理生成目标图像。在[11]之后,Li等人进一步引入了一个额外的术语来表示主机噪声[13]。虽然[12]和[13]都可以抑制图像中轻微的噪声,但它们在处理颜色失真和较大噪声方面能力不足。
基于深度学习的方法。随着深度学习的出现,一些低层次的视觉任务从深度模型中受益,如[14]、去噪[15]、超分辨率[16]、去压缩伪影[17]、去雾[18]。针对本文的目标任务,[19]中提出的微光网(low-light net, LLNet)构建了一个深度网络,同时作为对比度增强和去噪模块。Shen等人认为多尺度视网膜相当于具有不同高斯卷积核的前馈卷积神经网络。受此启发,他们构建了一个卷积神经网络(MSR-net)[20]来学习黑暗和明亮图像之间的端到端映射。Wei等人设计了一个深度网络,称为RetinexNet[21],它集成了图像分解和光照映射。请注意,Retinex-Net额外使用了一个现成的去噪工具(BM3D[22])来清洁反射率组件。这些策略都假定存在具有“地面真实”光的图像,而没有考虑到噪声对具有不同光的区域有不同的影响。简单地说,在提取了光照因子后,黑暗区域的反射率比明亮区域的噪声水平要高得多。在这种情况下,采用/训练具有均匀图像(反射率)能力的去噪器不再合适。此外,上述方法并没有明确地处理颜色失真的退化,这在真实图像中并不少见。最近,Chen等人提出了一种基于全卷积网络[23]端到端训练的低光图像处理管道,可以联合处理噪声和颜色失真。但是,这项工作只针对原始格式的数据,限制了它的适用场景。如[23]中所述,如果修改网络以接受JPEG格式的数据,性能会显著下降。
大多数现有的方法通过伽玛校正来控制光照,在精心构建的训练数据中指定一个水平,或融合。对于伽玛校正,它可能无法反映不同的光(曝光)水平之间的关系。至于第二种方式,严格限制在指定的职等是否包含在训练数据中。而对于最后一个,它甚至没有提供操作选项。因此,需要学习一种映射函数,可以任意地将一个光(曝光)级别转换为另一个光(曝光)级别,为用户提供灵活的调节。
图像去噪方法。 在图像处理、多媒体和计算机视觉领域,图像去噪一直是一个热门话题,在过去的几十年里提出了许多技术。经典模型利用自然图像的某些特定先验,如非局部自相似、分段平滑、信号(表示)稀疏性等,对问题进行建模/正则化。最流行的方案可能是BM3D[22]和WNNM[24]。由于测试优化过程的复杂性,以及合适参数的搜索空间较大,这些传统方法在实际应用中往往表现出较差的性能。最近,基于深度学习的去噪器在去噪任务上显示出了优越性。代表性的研究工作,如利用可训练的非线性反应扩散[27]进行叠式稀疏去噪的自动编码器[25]、[26]、TNRD、带有残差学习的DnCNN、批量归一化[15]等,在测试阶段只涉及前馈卷积运算,节省了计算量。然而,这些深度模型仍然存在图像盲去噪的困难。可以针对不同的层次训练多个模型,也可以训练一个具有大量参数的模型,这在实践中显然是不灵活的。通过在任务中考虑循环思想,这个问题得到了缓解。但是,上述方法都没有考虑到光增强图像的不同区域承载不同级别的噪声。同样的问题也发生在颜色失真上。
文章的贡献
- 受视神经网络理论的启发,该网络将图像分解为反射率和光照两个分量,将原始空间解耦为两个较小的空间
- 该网络使用在不同光线/曝光条件下捕获的成对图像进行训练,而不是使用任何地面真实反射率和照明信息
- 我们设计的模型提供了一个映射功能,可以根据用户的不同需求灵活地调整光的亮度。
- 提出的网络还包含一个模块,该模块能够通过亮暗区域有效地消除放大的视觉缺陷。
- 我们进行了大量的实验,以证明我们的设计的有效性和它的优越性,比目前最先进的选择。
数据使用与先验
在光照条件下没有明确的地面真相。此外,真实图像的地面真值反射率和光照图很少。层分解问题本质上是欠定的,因此附加的先验/正则化因子很重要。假设图像没有退化,某个场景的不同镜头应该具有相同的反射率。而光照图虽然可以强烈变化,但结构简单,相互一致。在实际情况中,在低光图像中体现的退化往往比在明亮图像中体现的退化更严重,这些退化将被转移到反射率部分。这启发了我们,在明亮的光线下,来自图像的反射率可以作为参考(地面真相),从退化的低光中学习修复者。有人可能会问,为什么不使用合成数据呢?因为它很难合成。这种降解不是简单的形式,而是根据不同的传感器而变化的。请注意,反射率(定义良好的)的使用完全不同于使用(相对)明亮的光作为参考的低光的图像。
层分解网络-(估计图像光照图与反射图)
从一个图像中恢复两个组件是一个高度不适定的问题。由于没有基于事实的信息指导,具有良好设计的约束的损失是很重要的。幸运的是,我们已经将不同的光/曝光配置的图像配对$[I_l,I_h]$。回想一下,某个场景的反射率应该在不同的图像之间共享,我们将分解的反射率对$[R_l,R_h]$调整为接近(如果没有退化,理想情况下是相同的)。此外,照明映射$[L_l,L_h]$应该是分段光滑和相互一致的。采用下列约束条件。
- We simply use
$ L_{rs}^{LD}:=\left \| R_l-R_h \right \|_{2}^{2} $regularize the reflectance similarity, where$ \left \| \cdot \right \|_2$means the$ l_2 $norm (MSE). - The illumination smoothness is constrained by
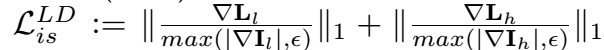 ,
,$ \bigtriangledown $stands for the first order derivative operator containing$ \bigtriangledown _x $(horizontal) and$ \bigtriangledown _y $(vertiacl) directions, and$ \left \| \cdot \right \|_1$means the$l^1 $norm.In addition,$ \epsilon $is a small positive constant (0.01 in this work) for avoiding zero denominator, and$ \left | \cdot \right |$means the absolute value operator. - 这个平滑项测量了照明相对于输入的相对结构。对于I中的一个边缘位置,L上的惩罚很小;而对于I中平坦区域的位置,惩罚会很大。至于相互之间的一致性,我们采用
$\mathcal{L}_{m c}^{L D}:=\|\mathbf{M} \circ \exp (-c \cdot \mathbf{M})\|_{1}$with$\mathbf{M}:=\left|\nabla \mathbf{L}_{l}\right|+\left| \nabla \mathbf{L}_{h}\right|$图4为u◦exp(−c·u)的功能行为,其中c为控制功能形状的参数,从图4可以看出,随着u的增加,惩罚先是上升,然后下降到0。这一特性很好地符合了相互的一致性,即保留较强的一致性边缘,抑制弱边缘。我们注意到,设置c=0会导致损失函数简化为$ l_1 $损失函数。 - 此外,分解后的两层应该再现输入,这受到重构误差的限制,
$$\mathcal{L}^{L D}:=\mathcal{L}_{r e c}^{L D}+0.01 \mathcal{L}_{r s}^{L D}+0.08 \mathcal{L}_{i s}^{L D}+0.1 \mathcal{L}_{m c}^{L D}$$
层分解网络包含两个分支,分别对应反射率和光照。反射支路采用典型的5层UNet[29],随后是卷积(conv)层和Sigmoid层。光照分支由两个conv+ReLU层和一个conv层组成,它们连接在反射率分支的特征映射上(可能会将纹理排除在光照之外),最后是一个Sigmoid层。详细的层分解网络配置如表1所示.
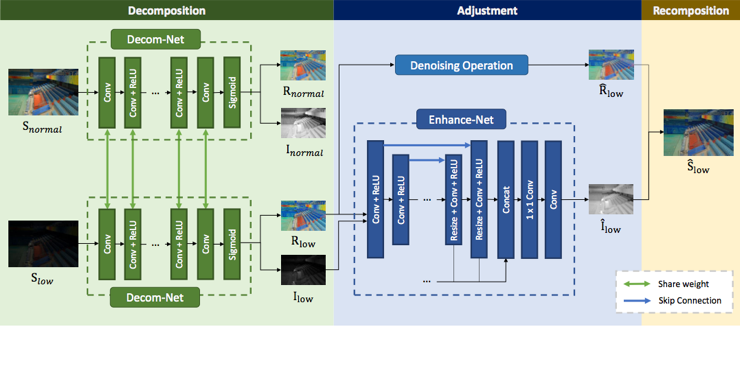
【RetinexNet】Deep Retinex Decomposition for Low-Light Enhancement
摘要
视网膜模型是一种有效的低光图像增强工具。它假设观测到的图像可以分解成反射率和照度。大多数现有的基于视网膜的方法都为这种高度不适定的分解精心设计了手工约束和参数,在各种场景中应用时可能受到模型容量的限制。在本文中,我们收集了一个包含低/正常光图像对的低光数据集(LOL),并提出了一个在此数据集上学习的深度视黄醇网络,包括用于分解的解码器和用于照明调节的增强器。在解解网的训练过程中,没有分解反射率和光照的地面真值。该网络只在关键约束条件下学习,包括由低/常光图像共享的一致反射率和光照的平滑度。在分解的基础上,通过增强网络增强光照,进行后续的明度增强;在联合去噪中,对反射率进行去噪。视网膜网是端到端的可训练的,所以学习的分解本质上有利于亮度调整。大量的实验结果表明,该方法不仅具有良好的低光增强效果,而且具有良好的图像分解效果。
网络结构
【CRM】A new low-light image enhancement algorithm using camera response model
摘要
微光图像由于能见度低,不利于人类的观察和计算机视觉算法。为了解决这一问题,人们提出了许多图像增强技术。然而,现有的技术不可避免地会在增加可见性时引入颜色和亮度失真。为了降低失真,我们提出了一种利用摄像机的响应特性进行增强的新方法。首先,我们研究了两幅不同曝光的图像之间的关系,以获得一个准确的相机响应模型。然后我们借用光照估计技术来估计曝光比图。最后,我们使用相机响应模型,根据估计的曝光率图调整每个像素的曝光值。实验结果表明,与现有的几种增强方法相比,该方法可以获得较低的色彩和亮度失真的增强效果。
看上去也是传统方法,重点应该在于camera response model:
相机响应模型由两部分组成:CRF模型和BTF模型。CRF模型的参数仅由相机决定,而BTF模型的参数由相机和曝光比决定。在本小节中,我们首先提出了基于两幅不同曝光图像观测的BTF模型。然后通过求解比较方程得到相应的CRF模型。最后,讨论了如何确定模型参数,给出了g的最终形式
【BIMEF】A Bio-Inspired Multi-Exposure Fusion Framework for Low-light Image Enhancement
微光图像由于能见度低,不利于人类的观察和计算机视觉算法。虽然许多图像增强技术已经被提出来解决这个问题,但现有的方法不可避免地会引入对比度过增强和欠增强。受人类视觉系统的启发,我们设计了一种用于微光图像增强的多曝光融合框架。基于该框架,我们提出了一种双曝光融合算法,以提供准确的对比度和亮度增强。具体来说,我们首先设计了基于光照es的图像融合权矩阵。
【LIME】: Low-Light Image Enhancement via Illumination Map Estimation
当一个人在弱光条件下拍摄图像时,图像的能见度通常很低。除了降低图像的视觉美感外,这种低质量还可能显著降低许多主要为高质量输入而设计的计算机视觉和多媒体算法的性能。本文提出了一种简单有效的微光图像增强方法。更具体地说,首先通过在R、G和B通道中寻找最大值来单独估计每个像素的光照。在此基础上,对初始光照图进行了细化.
重点在于光照图怎么估计? Max-RGB[8]是最早的颜色恒常性方法之一,它试图通过寻找R、G、b三个颜色通道的最大值来估计光照,但这种估计只能提高全局光照。在本文中,对于不均匀的照度,我们交替采用以下初始估计: …详细见论文
Retinex theory
中文名 视网膜大脑皮层理论
1963年12月30日E. Land作为人类视觉的亮度和颜色感知的模型在俄亥俄州提出了一种颜色恒常知觉的计算理论——Retinex理论。Retinex是一个合成词,它的构成是retina(视网膜)+cortex(皮层)→ Retinex。40多年来,工作在IS&T、NASA的J. J. McCann和D. J. Jobson、Zia-Ur Rahman、G. A. Woodell等人模仿人类视觉系统发展了Retinex算法,从单尺度Retinex算法(single scale retinex, SSR)改进成多尺度加权平均的Retinex算法(multi-scale retinex, MSR),再发展成带彩色恢复的多尺度Retinex算法(multi-scale retinex with color restoration, MSRCR)。