
GAN相关的论文概述
https://github.com/eriklindernoren/PyTorch-GAN#super-resolution-gan
什么是生成对抗网络
GANs是一个用于教学DL模型以捕获训练数据分布的框架,因此我们可以从相同的分布中生成新的数据。GANs由Ian Goodfellow在2014年发明,并首次在论文《生成式对抗网》中进行了描述。它们由两个不同的模型组成,一个生成器和一个鉴别器。生成器的工作是生成与训练图像相似的假图像。鉴别器的工作是查看图像并输出它是否是来自生成器的真实训练图像或假图像。在训练过程中,生成器不断尝试通过生成越来越好的假图像来智胜鉴别器,而鉴别器则努力成为更好的侦探,正确地对真假图像进行分类。这个游戏的平衡是当生成器生成看起来像是直接来自训练数据的完美假货时,鉴别器总是猜测生成器输出是真还是假的50%的可信度。
现在,让我们定义一些符号,在整个教程中使用,从discriminator开始。设x为表示图像的数据。D(x)是输出x来自训练数据而不是生成器的(标量)概率的鉴别器网络。这里,因为我们处理的是图像,所以D(x)的输入是CHW大小为3x64x64的图像。直观地说,当x来自训练数据时,D(x)应该是高的,而当x来自生成器时,D(x)应该是低的。D(x)也可以看作是传统的二进制分类器。
对于生成器s符号,设z为从标准正态分布中采样的潜在空间向量。G(z)表示将潜在向量z映射到数据空间的生成器函数。G的目标是估计训练数据来自的分布(pdata),这样它就可以从估计的分布(pg)生成假样本。
因此,D(G(z))是发生器G的输出是实像的概率(标量)。正如Goodfellow的论文所述,D和G玩一个极大极小的游戏,其中D试图最大限度地提高它正确分类实数和假货的概率(logD(x)),而G试图使D预测其输出为假货的概率最小(log(1−D(G(x)))。从文中可知,GAN损耗函数为
\underset{G}{\text{min}} \underset{D}{\text{max}}V(D,G) = \mathbb{E}_{x\sim p_{data}(x)}\big[logD(x)\big] + \mathbb{E}_{z\sim p_{z}(z)}\big[log(1-D(G(z)))\big]
GAN 的发展
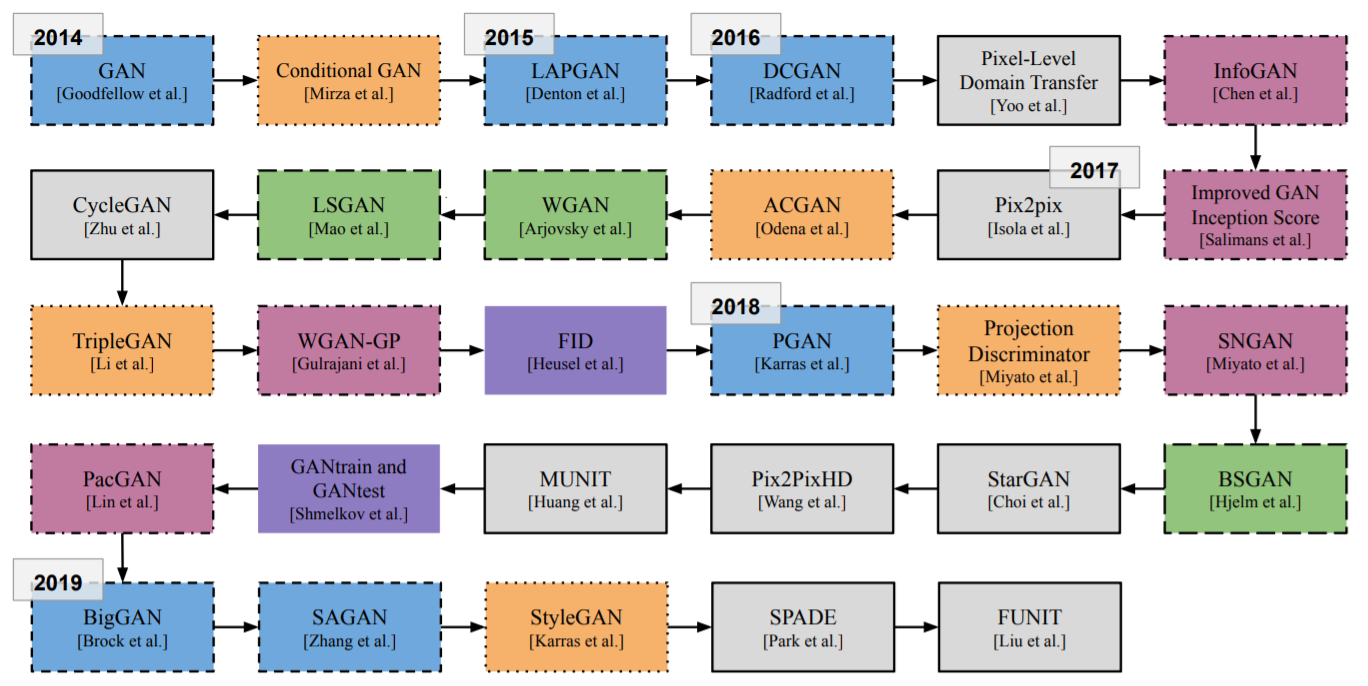 GAN 的时间线。就像我们的文本一样,我们将它分为六个方面(架构、条件技术、标准化和约束、损失函数、图像到图像的转换和验证度量),每个方面都用不同的颜色和不同的线/边框样式表示
GAN 的时间线。就像我们的文本一样,我们将它分为六个方面(架构、条件技术、标准化和约束、损失函数、图像到图像的转换和验证度量),每个方面都用不同的颜色和不同的线/边框样式表示
DCGAN
DCGAN是上述GAN的直接扩展,只是它在鉴别器和生成器中分别显式地使用了卷积和卷积转置层。Radford等人在论文《深度卷积生成对抗网络的无监督表示学习》中首次对其进行了描述。该鉴别器由strided convolution layers, batch norm layers, and LeakyReLU activations 组成。 输入是一个3x64x64的输入图像, 输出是一个标量概率, 输入是来自真实数据分布。该生成器由卷积转置层、批处理规范层和ReLU激活组成。输入是一个潜在向量z,它来自标准正态分布,输出是一个3x64x64的RGB图像。条纹的对流转置层允许潜在向量被转换成与图像形状相同的体积。在这篇论文中,作者也给出了一些关于如何设置优化器,如何计算损失函数,以及如何初始化模型权重的技巧,所有这些将在接下来的章节中进行解释。
BEGAN: Boundary Equilibrium Generative Adversarial Networks
The Six Fronts of the Generative Adversarial Networks
Cycle GAN
由于生活中成对的图片相对来说比较难取得,如果模型能从不配对的数据中学习,那么数据量会变得相对充足,于是Cycle gan就出现了。
 图像到图像的转换是一类视觉和图形问题,其目标是使用一组对齐的图像对来学习输入图像和输出图像之间的映射。然而,对于许多任务,成对的训练数据是不可用的。提出了一种学习方法,在没有成对实例的情况下,将图像从源域X转换为目标域Y。我们的目标是学习一个映射G: X→Y,使得来自G(X)的图像的分布可以通过一个有争议的损失从分布Y中得到。由于这种映射是高度欠约束的,我们可以将其与F: Y→X的逆映射进行组合,并引入一个循环一致性损失来强制F(G(X))≈X(反之亦然)。在不存在成对训练数据的情况下,定性分析结果被提出,包括集合样式转换、物体变形、季节转换、照片增强等。通过与已有方法的定量比较,证明了该方法的优越性。
图像到图像的转换是一类视觉和图形问题,其目标是使用一组对齐的图像对来学习输入图像和输出图像之间的映射。然而,对于许多任务,成对的训练数据是不可用的。提出了一种学习方法,在没有成对实例的情况下,将图像从源域X转换为目标域Y。我们的目标是学习一个映射G: X→Y,使得来自G(X)的图像的分布可以通过一个有争议的损失从分布Y中得到。由于这种映射是高度欠约束的,我们可以将其与F: Y→X的逆映射进行组合,并引入一个循环一致性损失来强制F(G(X))≈X(反之亦然)。在不存在成对训练数据的情况下,定性分析结果被提出,包括集合样式转换、物体变形、季节转换、照片增强等。通过与已有方法的定量比较,证明了该方法的优越性。
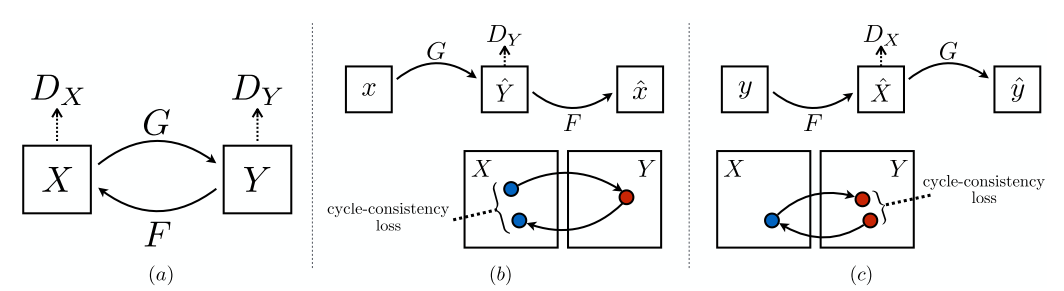 我们的模型包含两个映射函数G: X→Y和F: Y→X,以及相关的对抗鉴别器DY和DX。DY鼓励G X转化为输出的域Y,反之亦然,DX和F .进一步规范映射,我们介绍两个周期的一致性损失,捕捉直觉,如果我们翻译从一个域到另一个,回来我们应该到达我们开始的地方:(b)向前cycle-consistency失:X (X)→→G F (G (X))≈X, Y和(c)向后cycle-consistency损失:→F (Y)→G (F (Y))≈Y
我们的模型包含两个映射函数G: X→Y和F: Y→X,以及相关的对抗鉴别器DY和DX。DY鼓励G X转化为输出的域Y,反之亦然,DX和F .进一步规范映射,我们介绍两个周期的一致性损失,捕捉直觉,如果我们翻译从一个域到另一个,回来我们应该到达我们开始的地方:(b)向前cycle-consistency失:X (X)→→G F (G (X))≈X, Y和(c)向后cycle-consistency损失:→F (Y)→G (F (Y))≈Y
Cycle Consistency
使用传递性作为结构化数据正则化方法的思想由来已久。在视觉跟踪中,执行简单的前向-后向一致性几十年来一直是一个标准技巧[24,48]。在语言领域,通过“反向翻译和协调”来验证和改进翻译是人工翻译[3]和机器[17]使用的一种技术。近年来,高阶循环一致性被应用于从运动开始的结构[61]、三维形状匹配[21]、共分割[55]、密集语义对齐[65,64]和深度估计[14]。其中,Zhou等[64]和Go- dard等人的[14]与我们的工作最为相似,因为他们使用循环一致性损失作为一种利用传递性来支持CNN训练的方法。在这项工作中,我们引入了一个类似的损失来推动G和F相互一致。与我们的工作同时,在这些相同的过程中,Yi等人受机器翻译[17]中的双重学习启发,独立地使用一个类似的目标来进行非成对的图像到图像的翻译
怎么训练的?
BigGAN
丰富的背景和纹理图像的生成是各类生成模型追求的终极目标,ImageNet 的生成已然成为检验生成模型好坏的一个指标。
在各类生成模型中,GAN 是这几年比较突出的,18 年新出的 SNGAN [1]、SAGAN [2] 让 GAN 在 ImageNet 的生成上有了长足的进步,其中较好的 SAGAN 在 ImageNet 的128x128 图像生成上的 Inception Score (IS) [3] 达到了 52 分。BigGAN 在 SAGAN 的基础上一举将 IS 提高了 100 分,达到了 166 分(真实图片也才 233 分),可以说 BigGAN 是太秀了,在 FID [4] 指标上也是有很大的超越。
https://zhuanlan.zhihu.com/p/46581611 计算资源要求太高了
尽管生成图像建模最近取得了进展,但从ImageNet等复杂数据集中成功生成高分辨率、多样化的样本仍然是一个难以实现的目标。为此,我们尝试在最大的规模上训练生成的对抗网络,并研究针对这种规模的不稳定性。我们发现,应用正交正则化的生成器使它服从一个简单的截断技巧,允许通过减少生成器的输入的方差来精细地控制样本保真度和多样性之间的平衡。我们的修改导致模型设置新的艺术状态的类条件图像合成。当我们在ImageNet上以128 128的分辨率进行训练时,我们的模型(BigGANs)获得了一个初始值(IS)为166.5, Frechet Inception Distance(FID)为7.4,比之前的最佳值(52.52)和FID(18.65)有所提高。

https://tfhub.dev/deepmind/biggan-deep-512/1
SPADE —— 空间自适应归一化
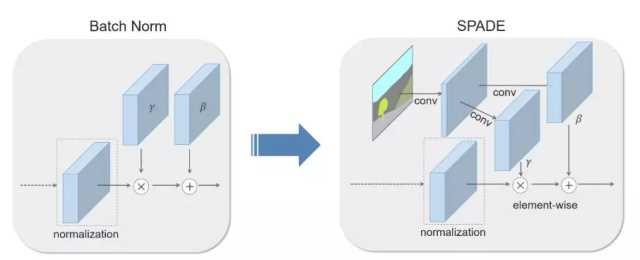
一些常见的归一化技术,比如批归一化(左图),往往在实际的归一化步骤之后应用学得的仿射层。而 SPADE 方法中的仿射层是从语义分割图中学习的。这与 Conditional Normalization 类似,不过 SPADE 中学得的仿射参数需要对空间自适应,也就是说对每个语义标签使用不同的 scaling 和偏置。使用这一简单的方法后,语义信号可以作用于所有层的输出,不受归一化过程的影响而丢失语义信息。此外,由于语义信息是由 SPADE 层提供的,因此随机 latent vector 可能作为网络的输入,来控制生成图像的风格。在 SPADE 中,掩码首先投射到一个嵌入空间,之后通过卷积运算生成调节参数(modulation parameter)γ 和 β。与已有的条件归一化方法不同,γ 和 β 不是向量,而是具有空间维度的张量。生成的 γ 和 β 经过乘法和加法后得到元素级的归一化激活值。
数据集
我们对几个数据集进行了实验。
- COCO- stuff[4]来源于COCO数据集[32]。它有118,000张训练图像和5,000张从不同场景捕获的验证图像。它有182个语义类。由于其巨大的多样性,现有的图像合成模型在这个数据集上表现很差。
- ADE20K[58]由20,210个训练和2,000个验证图像组成。与COCO类似,数据集包含150个语义类的具有挑战性的场景。
- ADE20K-outdoor是ADE20K数据集的子集,仅包含户外场景,在Qi等人的[43]中使用。
- Cityscapes数据集[9]包含德国城市的街景图像。培训和验证集的大小分别为3,000和500。最近的工作已经在Cityscapes数据集上获得了真实感语义图像合成结果[43,47]。
- Flickr的风景。我们从Flickr上收集了41,000张照片,并使用1,000个样本进行验证。为了避免昂贵的手工注释,我们使用一个训练有素的DeepLabV2[5]来计算输入分割掩码。
我们在相同的训练集上训练相互竞争的语义图像合成方法,并在每个数据集的相同验证集上报告它们的结果。
FUNIT:Few-Shot Unsupervised Image-to-Image Translation
文章一开始就指出,现有的image to image translation 尽管很成功,但在训练时需要很多来自source domain和target domain的图片。这篇文章的目标就是解决这种few-shot的问题,针对于此,本文设计了一种新的网络架构FUNIT,该网络可以利用测试时用少数图片学到source class到target class的映射。Image to image translation 发展到19年有两个问题:++
无监督的图像到图像的转换方法学习将给定类中的图像映射到另一个类中的类似图像,利用图像的非结构化(非注册)数据集。虽然非常成功,但是当前的方法需要在训练时访问源类和目标类中的许多图像。我们认为这极大地限制了它们的使用。从人类从少量实例中提取新对象本质的能力中获得灵感,并从中进行归纳,我们寻求一种少镜头、无监督的图像到图像的翻译算法。
无监督的图像到图像的转换方法学习将给定类中的图像映射到另一个类中的类似图像,利用图像的非结构化(非注册)数据集。虽然非常成功,但是当前的方法需要在训练时访问源类和目标类中的许多图像。我们认为这极大地限制了它们的使用。灵感从人类的能力捡一本小说的本质对象从一个小数量的例子和概括从那里,我们寻求few-shot,无监督image-to-image翻译算法,适用于前所未有的指定目标类,在测试时,只有几个例子图片。我们的模型通过将对抗训练方案与新颖的网络设计相结合,实现了这一能力。通过对基准数据集上几种基线方法的大量实验验证和比较,验证了该框架的有效性。我们的实现和数据集可以在https://github.com/NVlabs/FUNIT上找到。

网络结构
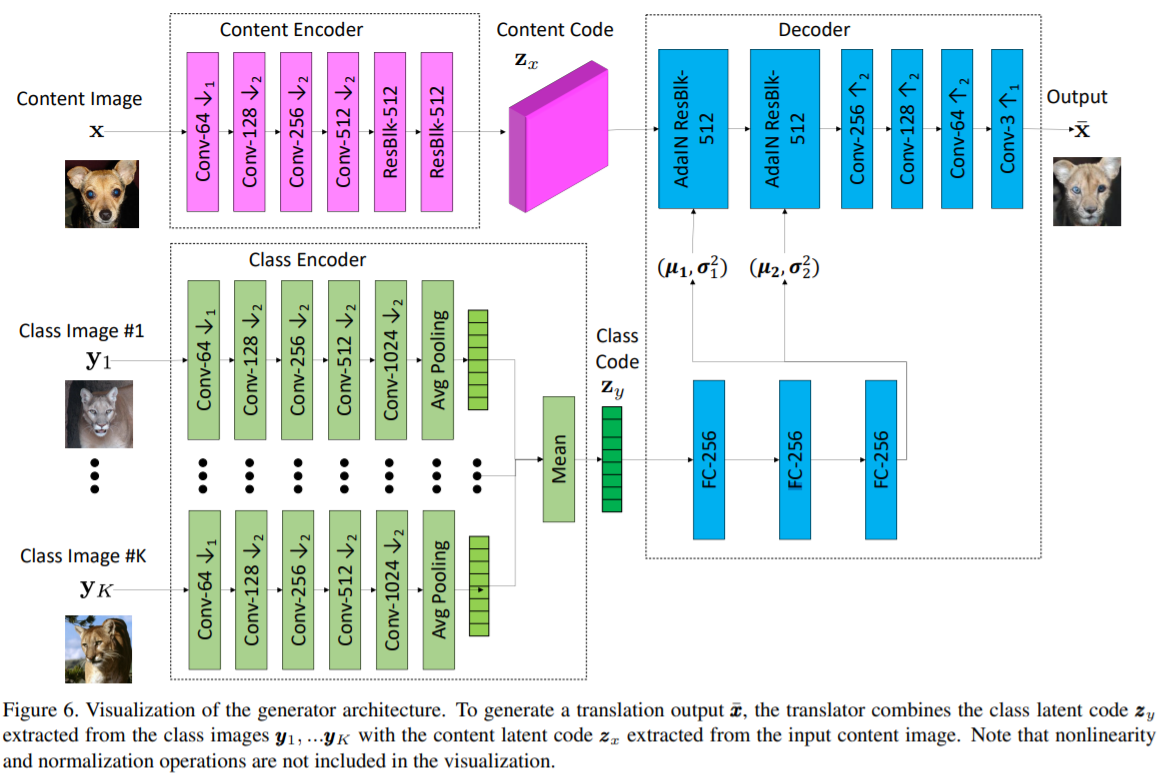
介绍
人类非常擅长概括。例如,当我们看到一种以前从未见过的珍奇动物的图片时,我们可以在脑海中形成一幅相同动物以不同姿势的生动画面,尤其是当我们以前遇到过类似但不同的动物以这种姿势时。例如,一个人第一次看到一只站着的老虎时,他会毫不费力地想象出它躺下时的样子,因为他一生都在和其他动物打交道。
虽然最近的无监督图像到图像的翻译算法在跨图像类传输复杂的外观变化方面非常成功[30,46,29,25,55,52],但是基于先验知识从一个新类的几个样本中进行泛化的能力完全超出了它们的能力范围。具体来说,他们需要大的训练集在所有类别的图像,他们要执行翻译,即,不支持小样本的泛化。
相关工作
我们的工作是基于部分共享的潜在空间假设,但设计的少镜头无监督的图像到图像的翻译任务。
现有的无监督图像到图像的翻译模型虽然能够生成真实的翻译输出,但存在两个方面的局限性。首先,它们是样本效率低,如果在训练时只给出很少的图像,就会产生糟糕的翻译输出。其次,所学习的模型仅适用于在两个类之间转换图像。一个翻译任务的训练模型不能直接用于新任务,尽管新任务与原始任务之间存在相似性。例如,虽然cat和tiger有很大的相似之处,但是不能将husky-to-cat翻译模型用于husky-to-tiger翻译。
最近,Benaim和Wolf提出了一个无监督的图像到图像的翻译框架来部分解决第一个方面。具体来说,他们使用由一个源类图像和多个目标类图像组成的训练数据集来训练一个模型,用于将单个源类图像转换为目标类的类似图像。我们的工作在几个主要方面与他们的不同。首先,我们假设有很多源类映像,但是很少有目标类映像。此外,我们假设少数目标类映像只在测试时可用,并且可以来自许多不同的对象类。
多类无监督图像到图像的翻译将无监督的图像到图像的转换方法扩展到多个类。我们的工作类似于这些方法。但是,我们不是在可见类之间转换图像,而是将可见类的图像转换为类似的、以前未见过的类的图像。
少镜头分类。与少镜头图像到图像的翻译不同,使用少量例子学习新类的分类器是一个长期研究的问题。早期的作品使用了外观的生成模型,这些模型以分层的方式在不同的类别之间共享先验[11,39]。最近的研究集中在使用元学习来快速调整模型以适应新的任务[12,35,38,34]。这些方法学习了更好的训练优化策略,使得仅看到少数例子的性能得到了提高。另一组作品关注于更适合少镜头学习的图像嵌入方法[49,43,44]。最近的一些研究提出通过生成与新类相对应的新特征向量来扩充少镜头分类任务的训练集[10,15,51]。我们的工作是为少镜头无监督的图像到图像的翻译。然而,它可以应用于少镜头分类,如实验部分所示。
少镜头翻译用于少镜头分类。我们使用动物和鸟类的数据集来评估FUNIT的少镜头分类。具体来说,我们使用经过训练的FUNIT模型为每个少镜头的类生成N(从1,50到100)张图像,并使用生成的图像训练分类器。我们发现FUNIT生成图像的分类器训练比Hariharan提出的few-shot分类方法S&H持续取得更好的性能[15]。S&H是基于功能幻觉,也有一个可控变量样本数量n的方法.实验结果如表3所示,详细给出了附录H。
正如在主要论文中提到的,我们进行了一个实验,使用FUNIT生成器生成的图像,使用动物面孔和北美鸟类数据集,在一次性设置下训练新类别的分类器。根据Hariharan等人[15]的设置,我们创建了5个不同的一次性训练片段,每个片段都有一个训练集、验证集和测试集。训练集由|T|图像组成,每个|T|测试类中的一个图像。验证集由每个测试类的20-100个图像组成。测试集由剩余的测试类映像组成。
我们使用FUNIT生成器生成一个合成训练集,使用分类训练集中的图像作为类图像输入,并从源类中随机采样图像作为内容图像输入。我们使用原始训练集和合成训练集来训练分类器。我们将我们的方法与Hariharan等人的Shrink and Hallucinate(S&H)方法进行了比较,该方法学习生成与新类相对应的最终层特征。我们使用一个预训练的10层ResNet网络作为特征提取器,该特征提取器完全使用源类图像进行预训练,并在目标类上训练一个线性分类器。我们发现在生成的图像上对损失的权重要低于真实图像。我们使用验证集对权重值和权重衰减值进行了详尽的网格搜索,并报告了测试集的性能。为了进行公平的比较,我们还对S&H方法进行了同样的详尽的搜索。
在主要论文的表3中,我们报告了我们的方法和S&H方法[15]在不同数量的生成样本上的性能。这是两项具有挑战性的细粒度分类任务。这两种方法的性能都优于基线分类器,后者仅对每个新类使用单一提供的真实图像。使用我们生成的图像,我们获得了大约2%的改进超过S&H方法生成的特征.
对基础10层ResNet网络进行90个epoch的训练,初始学习率为0.1,每30个epoch衰减10倍。线性分类器在新类上的权值衰减是从15个对数间隔值(包括0.000001和0.1)中选择的。生成的图像和特征的损失乘数是从7个对数间隔值(包括0.001和1)中选择的。权重衰减和损耗倍增器的值是根据在Split #1 上训练时获得的最佳验证集精度来选择的。然后这些值被固定,并用于所有剩余的Split#2-5。使用固定特征学习L2正则分类器的任务是一个凸优化问题,我们使用L-BFGS算法进行线性搜索,因此不必指定学习速率。
在表6和表7中,我们报告了所有5个单次分割的动物面孔和北美鸟类数据集的测试准确性及其相关方差。在所有的实验中,我们只学习一个新的分类器层使用的特征提取的网络训练的一组类用来训练图像生成器。
我们的方法也可以与现有的少镜头分类方法相结合。在表8中,我们展示了使用原型网络方法[43]获得的一次分类结果,该方法将从给定的几个火车样本中获得的最接近的原型(集群中心)的标签分配给一个测试样本。显然,使用我们生成的样本以及在测试时每个类提供的1个样本来计算类原型表示有助于提高这两个数据集的准确性(超过5.5%)。
怎么训练的?
TOWARDS UNSUPERVISED SINGLE IMAGE DEHAZING WITH DEEP LEARNING
基于Cycle GAN 做的,效果也没有很好,还是有很大提升空间的
数据集是 RESIDE
具体来说,高感知损失被引入来优化一个使用特征空间而不是像素空间[15]的单图像去雾模型。[16,17]利用基于gan的对抗损失进一步增强生成的干净图像的视觉质量。这种基于感知损失的数据驱动方法提高了整体去雾性能。然而,大多数最先进的数据驱动方法需要一组退化和地真深度/无雾图像对来学习增强给定退化图像的模型。虽然CycleGAN[15]中最近出现的周期一致性损失已经消除了成对训练数据的需要,但是干净的图像仍然是监督网络训练的必要条件。
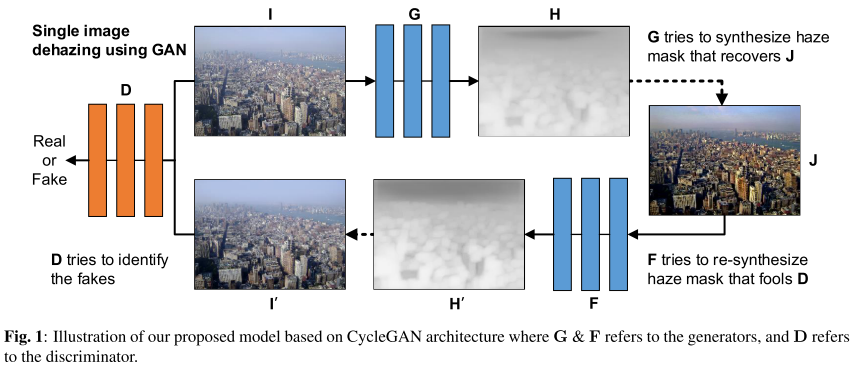
在提出的模型中,我们训练了一个端到端网络,该网络基于CycleGAN架构,将对抗损失与周期一致性损失相结合,从模糊的图像中获得清晰的图像。我们不使用生成网络从其朦胧的版本直接产生一个干净的图像。相反,我们利用生成器作为工具来提取烟雾掩膜,然后获得清洁图像使用重新制定的大气散射模型。我们的模型的训练策略是,当我们重新合成雾霾掩模和获得的清洁图像时,重建的雾霾图像应该与原始的雾霾图像相似。在这种方法中,我们的模型学习了什么是雾霾,而不是图像去雾的问题,这就免除了地面真实干净或深度图像的要求。