
数据库的一些知识点总结
数据库的一些知识点总结
事务隔离
事务,就是要保证一组数据库操作,要么全部成功,要么全部失败。
隔离性
- 读未提交
- 读提交
- 可重复读
- 串行化(读写锁)
日志系统
- redo log (重做日志)
- binlog (归档日志)
redo log(重做日志)
MySQL中,每一次更新操作都需要写进磁盘,然后磁盘也要找到对应的记录,然后再更新,整个过程IO成本、查找成本高
- WAL技术 全称 Write-Ahead Logging 关键在于先写日志,再写磁盘。
- 具体:当有记录需要更新时,InnoDB引擎会先把记录写到redo log中,再系统比较空闲时更新至磁盘。
有了redo log InnoDB可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个能力称为 crash-safe。
binlog (归档日志)
最开始的MySQL里无 InnoDB, MySQL自带的引擎是MyISAM,但其没有crash-safe能力
- binlog是MySQL的Server层实现的,所有引擎都可以使用
- redo为物理日志,记录具体修改的内容。二binlog是逻辑日志,记录语句原始逻辑
- redo log是循环写的,空间会用尽;而binlog可追加写入
基础架构
graph LR
客户端-->连接器
连接器-->分析器
分析器-->优化器
优化器-->执行器
- 连接器–管理连接,权限验证
- 分析器–词法分析,语法分析
- 优化器–执行计划生成,索引选择
- 存储引擎– 存储数据,提供读写接口
SQL必知必会
- 关键字的顺序是不能颠倒的:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...
-
执行顺序: FROM > WHERE > GROUP BY > HAVING > SELECT的字段 > DISTINCT > ORDER BY > LIMIT
-
降序 DESCENTING DESC
-
BETWEEN AND
-
通配符%
-
_[^ab]% 第二位不为ab的串
-
联结表
- 普通联结 用 WHERE a.ID = b.ID
- 内联结 a INNER JOIN b ON a.ID = b.ID
- 联结表开销较大,尽量减少
- INNER JOIN(内联):两个表a,b 相连接,取出符合连接条件的字段
- LEFT JOIN(左联):先返回左表的所有行,再加上符合连接条件的匹配行
- RIGHT JOIN(右联):先返回右表的所有行,再加上符合连接条件的匹配行
-
删除:删除表中的数据的方法有delete,truncate, 其中TRUNCATE TABLE用于删除表中的所有行,而不记录单个行删除操作。TRUNCATE TABLE 与没有 WHERE 子句的 DELETE 语句类似;但是,TRUNCATE TABLE 速度更快,使用的系统资源和事务日志资源更少。
-
MySQL IFNULL() 函数,IFNULL(expression, alt_value) 第一个参数为 NULL: SELECT IFNULL(NULL, “RUNOOB”); 以上实例输出结果为: RUNOOB 第一个参数不为 NULL: SELECT IFNULL(“Hello”, “RUNOOB”); 以上实例输出结果为: Hello
排序
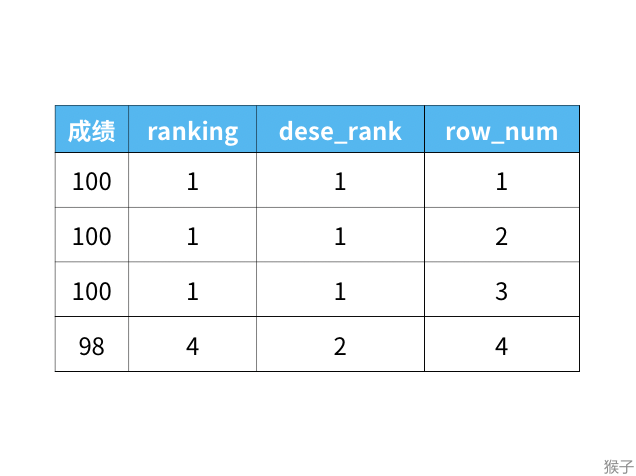
1)rank函数:这个例子中是5位,5位,5位,8位,也就是如果有并列名次的行,会占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,4。
2)dense_rank函数:这个例子中是5位,5位,5位,6位,也就是如果有并列名次的行,不占用下一名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,结果是:1,1,1,2。
3)row_number函数:这个例子中是5位,6位,7位,8位,也就是不考虑并列名次的情况。比如前3名是并列的名次,排名是正常的1,2,3,4。
over函数的用法
over不能单独使用,要和分析函数:rank(),dense_rank(),row_number()等一起使用。 执行语句:select row_number() over(order by AID DESC) as rowid,* from bb
作者:houzidata 链接:https://leetcode-cn.com/problems/rank-scores/solution/tu-jie-sqlmian-shi-ti-jing-dian-pai-ming-wen-ti-by/ 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
联结
分解数据为多个表能更有效地存储,更方便地处理,并且具有更大的可伸缩性。如果该数据存储在多个表中,如何用单条select语句检索出数据?
联结是一种机制,用来在一条select中关联表,因此称之为联结。SQL最强大的功能之一是能在数据检索查询的执行中联结(join)表。
(1)创建联结
Select vend_name,prod_name,prod_price
From vendors,products
Where vendors.vend_id = products.vend_id
Order by vend_name,prod_name;
在上面的代码中,Select指定检索列,不过与之前的差别是其中的两个列在products表中,另一个在vendors表中。From指定了两个表,这两个表为select语句联结的两个表名。而Where子句指示MySQL匹配vendors中的vend_id和products中的vend_id,在这里要匹配的两个列使用完全限定列名进行指定。完全限定列名是指在引用的列可能出现二义性时,必须使用完全限定列名(用一个点分隔的表名和列名)。
在一条select语句中联结几个表时,相应的关系是在运行中构造的。在表定义中不存在能指示MySQL如何对表进行联结的东西。在联结两个表时,实际上是将第一个表中的每一行与第二个表中的每一行配对,where子句作为过滤条件,它只包含那些匹配给定条件的行。没有where子句,无论它们逻辑上是否可以配在一起,第一个表中的每个行都将与第二个表中的每个行配对。
上面所用的联结称为等值联结,它基于两个表之间的相等测试,也称为 内部联结 。也可以用不同的语法返回与前面例子完全相同的数据:
索引
什么是索引
目录,加快数据库的查询速度。类同于书的目录。
select * from table1 where id = 44
如果没有索引,必须遍历整个表,直到ID=44这行。时间复杂度为O(n),而有索引就可以在ID这一列找,使之快速定位。
建立索引的目的是加快对表中记录的查找与排序。
但是为表设置索引要付出代价。一是增加了数据库的存储空间,二是在插入与修改数据时要花费较多的时间(需要维护索引)
数据结构
- 哈希表常用于等值查询的场景
- 有序数组再等值和范围查询场景中性能都很优秀
- 有序数组索引只适用于静态存储引擎,因为其需要更新数据时,时间复杂度是O(N),开销大
- 二叉树是搜索效率最高的,但实际上大多数数据库存储使用多叉树
- 由于磁盘读取耗时,二叉树的树较高,使用多叉树可以减少树高,降低IO次数
- InnoDB 这个N差不多1200
InnoDB的索引模型
InnoDB使用了B+树作为索引模型,其表都是根据主键顺序以索引形式存放的。
主键索引的叶子节点存的是整行数据。主键索引也被称为聚簇索引。
非主键索引的叶子节点内容是主键的值。故其被称为二级索引。
普通索引
普通索引完成一次查询后,需要先搜索其索引树,得到主键索引的值,回表至主键索引再搜索一次。故尽可能使用主键索引,少使用普通索引。
索引维护
B+树为了维护索引有序性,再插入新值时需要做必要的维护。
覆盖索引
覆盖索引不需要回表。普通索引就可覆盖查询需求。 故其可以减少树的搜索次数,提升查询性能。但是依然会产生维护开销。
最左前缀原则
对于 (name,age)索引其实相当于(name,age)与(name)索引
为什么要创建索引
- 创建唯一性索引,可保证数据库表中每一行数据的唯一性
- 可以大大加快数据的检索速度,这是创建索引的最主要原因
- 加速表与表之间的连接,?实现数据的参考完整性方面有意义
- 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间
B+ 树基于 B 树做出了改进,主流的 DBMS 都支持 B+ 树的索引方式,比如 MySQL。B+ 树和 B 树的差异在于以下几点:
- 有 k 个孩子的节点就有 k 个关键字。也就是孩子数量 = 关键字数,而 B 树中,孩子数量 = 关键字数 +1。
- 非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最小)。
- 非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而 B 树中,非叶子节点既保存索引,也保存数据记录。
- 所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大顺序链接。
一、数据库索引,为什么不适用用二叉树:
- 平衡二叉树必须满足(所有节点的左右子树高度差不超过1)。执行插入还是删除操作,只要不满足上述条件,就要通过旋转来保持平衡,而旋转是非常耗时的,所以AVL树适合用于查找多的情况。
- 二叉树的数据结构,会导致“深度”,比较深,这种“瘦高”的特性,加大了平均查询的磁盘IO次数,随着数据量的增多,查询效率也会受到影响;
二、B+ 树和 B 树在构造和查询性能上有什么差异呢? B+ 树的中间节点并不直接存储数据。
- B+树的查询效率更加稳定:由于非终结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
- B+树的磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对B树更小,如果把所有同一内部节点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。 3、由于B+树的数据都存储在叶子结点中,分支结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,所以通常B+树用于数据库索引。